Kiesel Devlog #10: Let's Make It Fast!
Published on 2024-08-19.Over the last year and a bit Kiesel has grown beyond being a small experiment. I've been churning out feature after feature, and while correctness has been of importance from day one, one thing hasn't been on my radar as much: performance.
You could go as far as saying Kiesel is blazingly slow 🔥. Let's change that :^)
Make It Work
This part is done, it works. Some things better than others, the object model is rock solid for instance (a lesson learned from LibJS), while others fall apart if you look at them the wrong way (looking at you, src/language/bytecode/Vm.zig). The secret here is to make it work most of the time, which gets you pretty far.
At the time of writing Kiesel passes 59.2% of test262, so things are clearly going into a good direction.
I've also been untying various bits of runtime code from the VM recently and am mentally prepared to throw that part away and start over. Making it work all the time is on the horizon.
Make It Right
As mentioned I made sure that everything's following the spec as much as reasonably possible, which is another lesson I learned from working on LibJS. Back then I spent many months fixing countless correctness issues after excitement died down and most early contributors moved on. Let's just say MDN has fantastic docs but it's not a very good reference for writing a JS engine.
Of course there are still correctness bugs in Kiesel, some of them yet to be found, some of them known. The former will be flushed out by test262 eventually and I try to clearly mark all of the latter with TODOs. Frequently they are results of cutting corners for the sake of quick progress, such as number parsing which defers to Zig's std.fmt.parseFloat() and std.fmt.parseInt() with some basic upfront validation. Not having to write a floating point parser was a welcome shortcut at the time :^)
Oh, and so many RegExp parsing bugs. Probably need to rewrite that too.
Make It Fast
I'm occasionally talking with Jason — original creator of the Boa JS engine — about all things engine development. A few months ago he mentioned they set up a benchmarks page which uses an old version of the V8 Benchmark Suite to compare Boa against various other engines. I was keen to add Kiesel but at the time it couldn't even parse the entire benchmark suite, so we abandoned that idea.
Recently I tried again and a few bug fixes later Kiesel was able to run the whole thing to completion! There's just one problem: it was slow. Like an hour while most engines complete within a few minutes slow. Armed with perf(1) and speedscope I got to work :^)
Improving Expression and Statement Parsing
[source]
The very first thing I found was a shocking amount of time spent in the parser! Kiesel has a hand-written parser using the parser-toolkit library, which allows for patterns that lead to very readable code at the expense of becoming quite inefficient for large grammars.
We were effectively brute forcing our way through all possibilities using Zig's error-unwrapping if/else:
pub fn acceptPrimaryExpression(self: *Self) AcceptError!ast.PrimaryExpression {
const state = self.core.saveState();
errdefer self.core.restoreState(state);
if (self.core.accept(RuleSet.is(.this))) |_|
return .this
else |_| if (self.acceptIdentifierReference()) |identifier_reference|
return .{ .identifier_reference = identifier_reference }
else |_| if (self.acceptLiteral()) |literal|
return .{ .literal = literal }
else |_| if (self.acceptArrayLiteral()) |array_literal|
return .{ .array_literal = array_literal }
else |_| if (self.acceptObjectLiteral()) |object_literal|
return .{ .object_literal = object_literal }
// ... snip ...
else |_|
return error.UnexpectedToken;
}This statement had 15 branches so in the worst case you'd have 14 failed attempts of progressing the parser including state restores until arriving at the right accept function. We can do much better!
The code now looks at the next token and switches on it, which is less readable but means we can immediately pick the right code path:
pub fn acceptPrimaryExpression(self: *Self) AcceptError!ast.PrimaryExpression {
const state = self.core.saveState();
errdefer self.core.restoreState(state);
const next_token = try self.core.peek() orelse return error.UnexpectedToken;
return switch (next_token.type) {
.this => blk: {
_ = self.core.accept(RuleSet.is(.this)) catch unreachable;
break :blk .this;
},
.identifier, .yield, .@"await" => if (self.acceptIdentifierReference()) |identifier_reference|
.{ .identifier_reference = identifier_reference }
// ... snip ...
else |_|
error.UnexpectedToken,
.@"[" => .{ .array_literal = try self.acceptArrayLiteral() },
.@"{" => .{ .object_literal = try self.acceptObjectLiteral() },
.numeric, .string, .null, .true, .false => .{ .literal = try self.acceptLiteral() },
// ... snip ...
else => error.UnexpectedToken,
};
}Lazy Global Object Properties
[source]
I implemented intrinsics (the underlying objects behind things like Array and Array.prototype) with lazy initialization in mind from the beginning, allocating everything upfront is wasteful. This works by having a function like this returning Allocator.Error!Object:
try realm.intrinsics.@"%Array.prototype%"();If the intrinsic has never been accessed before, it will be allocated on the heap and initialized. After that it's a guaranteed allocation-free lookup. The only problem is that the global object would initialize every single constructor and its prototype on startup, making this extra step pointless.
I had to do a bit of surgery to still create those properties upfront but only initialize their value (an intrinsic object) when it is first being looked up from the property storage. This makes creation of the global object and thus startup times much faster as demonstrated here by running an empty script:
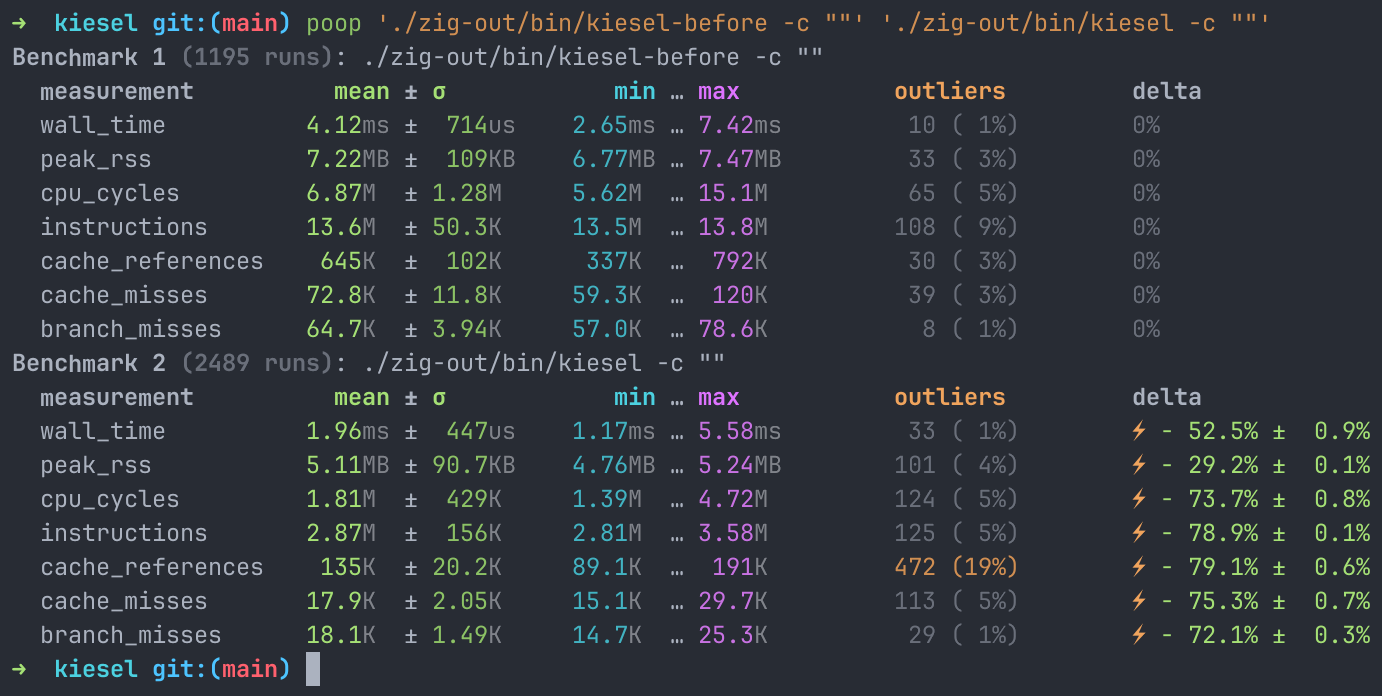
Making the AST Less Allocation-Heavy
[source]
A common pattern in the AST is to recursively collect a list of something from a node and all of its children, e.g. a function's var declared names for scoping purposes. This used to be done with each node creating a std.ArrayList for its own var declared names and returning the final result as an immutable slice, i.e. []const ast.Identifier. Parent nodes would collect these and join them together.
All of this incurred a significant allocation overhead, especially with std.ArrayList allocating more space upfront every time it needs to grow. With that in mind I figured a much better solution would be to only ever create one such list and pass it around to not waste any memory from merging and throwing away intermediate results. This means the caller now owns the std.ArrayList and child nodes recursively pass it to collectVarDeclaredNames():
-const var_names = try code.varDeclaredNames(agent.gc_allocator);
-defer agent.gc_allocator.free(var_names);
+var var_names = std.ArrayList(ast.Identifier).init(agent.gc_allocator);
+defer var_names.deinit();
+try code.collectVarDeclaredNames(&var_names);
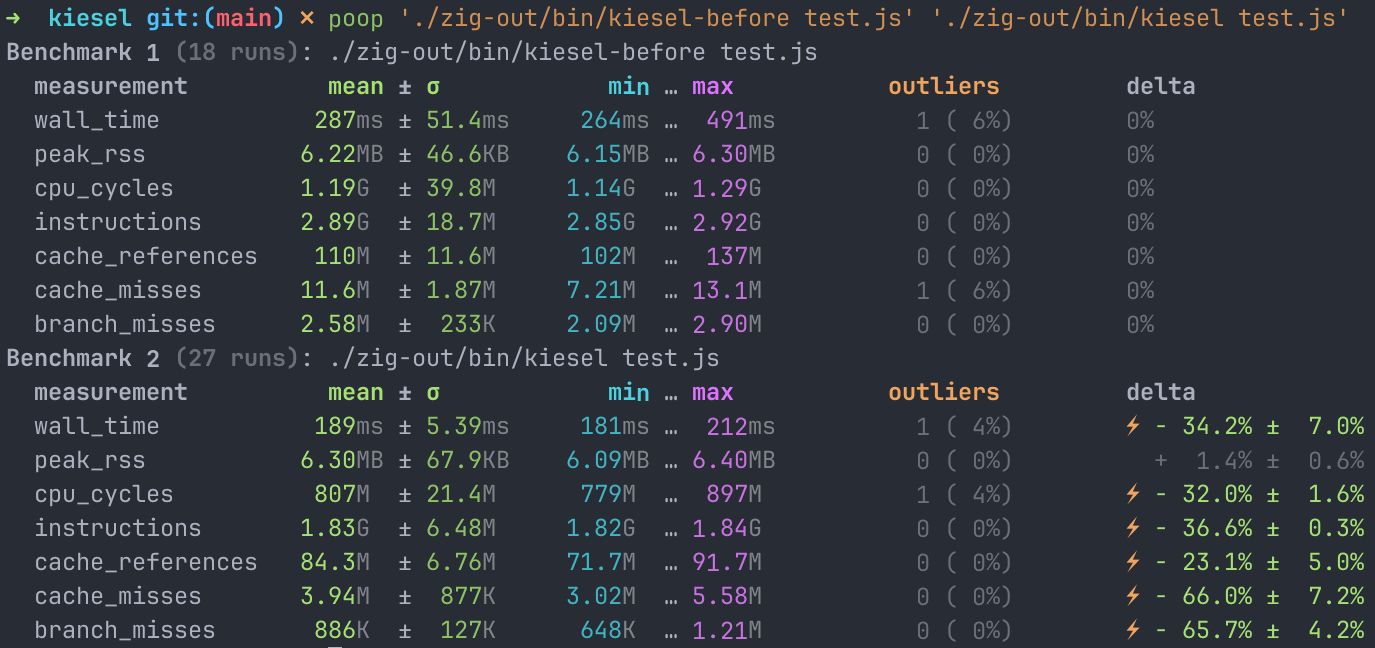
Results for this microbenchmark look as follows:
function foo() {
var a;
{
var b;
{
var c;
{
var d;
{
var e;
}
}
}
}
}
for (var i = 0; i < 50_000; ++i) {
foo();
}
Later on I also tried to cache these results across function runs, but the results didn't convince me.
Optimizing Array Truncation via .length
[source]
Another interesting bottleneck I found was array truncation by setting the length property to a lower value than before, e.g.:
const a = [1, 2, 3, 4, 5];
a.length = 3; // a -> [1, 2, 3]In that case we would collect all numeric property keys, sort them in descending order, and delete them one by one up to the new length. If that sounds a lot like a backwards for loop to you that's because it really should be one :^)
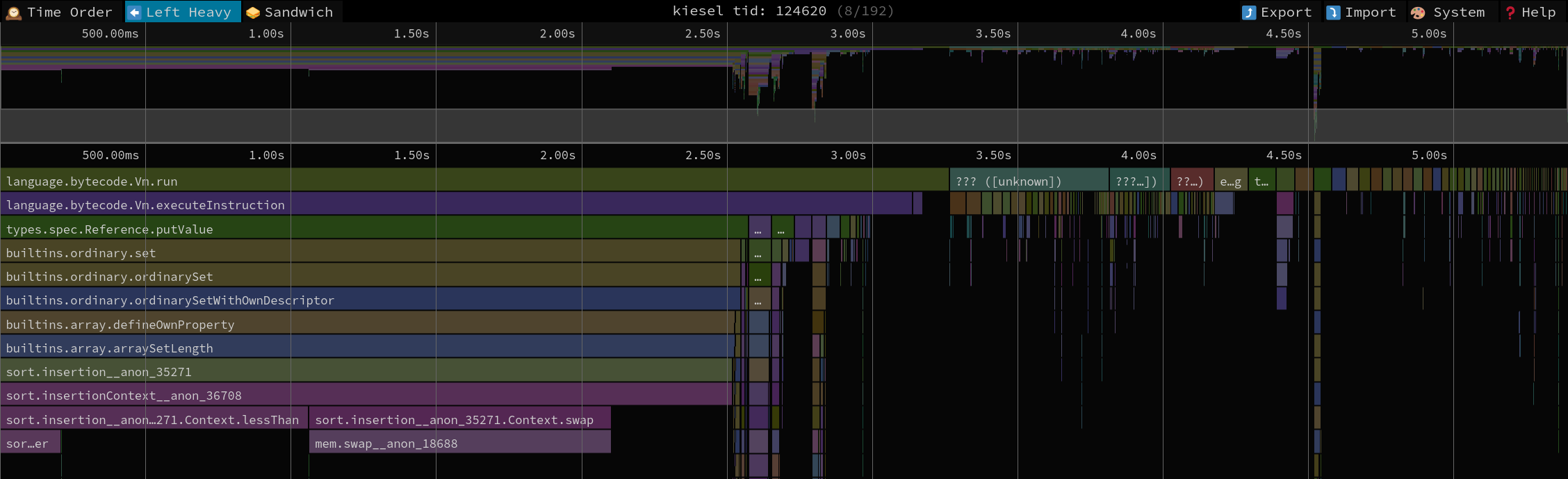
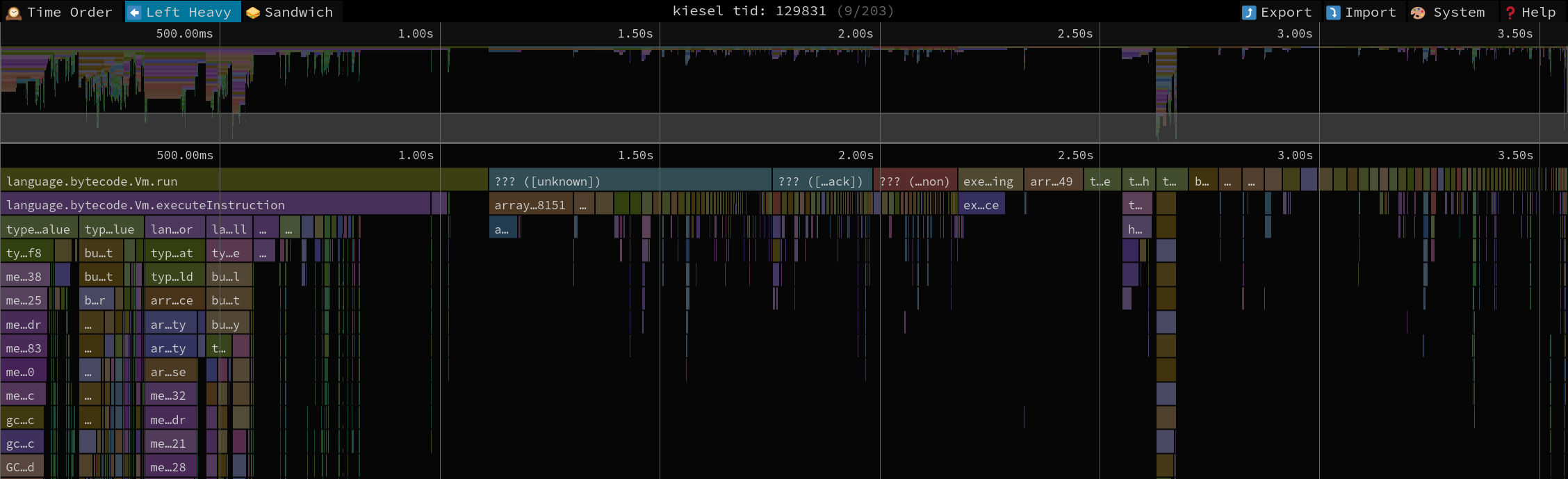
I ended up with a hybrid solution that uses a threshold for switching between either mechanism to not turn something like this into a performance cliff:
const a = [];
a[1_000_000_000] = 123;
a.length = 0; // One billion iterations to check for numeric properties to deleteAvoiding UTF-8 Conversion Churn in Bindings
[source]
Strings in Kiesel have a complicated history: they used to be UTF-8 as that's all modern software should deal with, but are specified to be UTF-16 in ECMAScript and may contain unpaired surrogates which cannot be present in valid UTF-8. These shortcomings as well as the additional complexity from transcoding between UTF-8 and UTF-16 on the fly led to a big refactor to store strings either as a sequence of u8 for ASCII or as a sequence of u16 for UTF-16. This makes indexing (accessing a single code unit) O(1) and generally simplifies a few things.
While doing that refactor I left the code dealing with bindings (the foo in let foo = 42;) untouched, these were still assumed to be UTF-8 (as is the source code that Kiesel parses). Once more this led to a number of on the fly conversions between UTF-8 and UTF-16, and even for the simple ASCII to UTF-8 case we'd end up making a full copy of the string.
Long story short, I updated all of that to use the same underlying String type as regular JS values and the problem went away :^)
Shrinking Objects for Memory Savings Fun and Profit
Not all performance work is about achieving better Big-O, there's another classic: "allocations are slow". And well, that's not entirely wrong, especially when allocating means generating garbage that needs to be collected later on. You know, like in JS. I've seen profiles where over time the heap would grow to 10GB+ and virtually all time was spent in garbage collection!
The number one reason for heap allocations in JS ought to be objects, so I looked into those. Right now the implementation is a really straightforward property key (string, symbol, or number) to property descriptor (value or getter/setter pair for accessors, three attributes stored as boolean flags) mapping. The only issue is that partial property descriptors can exist in a few situations so all the fields have to be nullable (including a funky double-nullable Object):
const PropertyDescriptor = struct {
value: ?Value = null, // 24 bytes
writable: ?bool = null, // 2 bytes
get: ??Object = null, // 24 bytes
set: ??Object = null, // 24 bytes
enumerable: ?bool = null, // 2 bytes
configurable: ?bool = null, // 2 bytes
}; // 2 bytes (padding)
// -> 80 bytes!Additionally a populated property descriptor will have either of these fields set, never an intersection of them:
value,writable,enumerable,configurable("data descriptor")get,set,enumerable,configurable("accessor descriptor")
With that in mind we can design this as a tagged enum instead:
// PropertyStorage.zig
const Entry = union(enum) { // 8 bytes (enum tag + padding)
accessor: struct {
get: ?*Object.Data, // 8 bytes
set: ?*Object.Data, // 8 bytes
attributes: Attributes, // 3 bytes
}, // 5 bytes (padding)
// -> 24 bytes
data: struct {
value: Value, // 16 bytes
attributes: Attributes, // 3 bytes
}, // 5 bytes (padding)
// -> 24 bytes
const Attributes = packed struct(u3) {
writable: bool,
enumerable: bool,
configurable: bool,
};
};
// -> 32 bytes :^)Much better!
Avoiding Number-To-String Conversions for Property Keys
[source]
It's a common misconception that JS has "numeric" property keys; it does not. foo[0] is the exact same thing as foo["0"] — yes, those wacky type coercions :^)
However, engines can use the opportunity to store property keys that also happen to be positive integers as such internally, and Kiesel is no exception. For instance we can then store those property values in an actual array with linear indexing instead of a hashmap.
When it comes to these little unobservable diversions from the spec it's easy to miss additional work that no longer needs to be done. In this case I noticed something in the ToPropertyKey abstract operation:
The abstract operation ToPropertyKey takes argument
argument(an ECMAScript language value) and returns either a normal completion containing a property key or a throw completion. It convertsargumentto a value that can be used as a property key. It performs the following steps when called:1. Let key be ? ToPrimitive(argument, string). 2. If key is a Symbol, then a. Return key. 3. Return ! ToString(key).
Since the spec only deals with strings and symbols as property keys it unconditionally does that ToString at the end, but we can insert an extra step to check coercing key to a primitive value resulted in a number and then use that!
And a Few Others…
…that I won't explain in detail here because they're a bit boring. Feel free to take a look yourself :^)
language: Determine if an arguments object will be needed during parsinggc: Enable parallel markingtypes: Compute string hashes once upfront- A number of commits related to making
Valuefit into 8 bytes, which will get its own blog post!
Results
Was it worth it? Absolutely!
Comparing the last commit before the first optimization mentioned above (33e5444) with main (e972e9c at the time of writing) we get massive improvements across the board — the V8 benchmark suite (here combined.js) now completes in five minutes instead of 50! We also peak at less than 2GB of memory instead of 9GB.
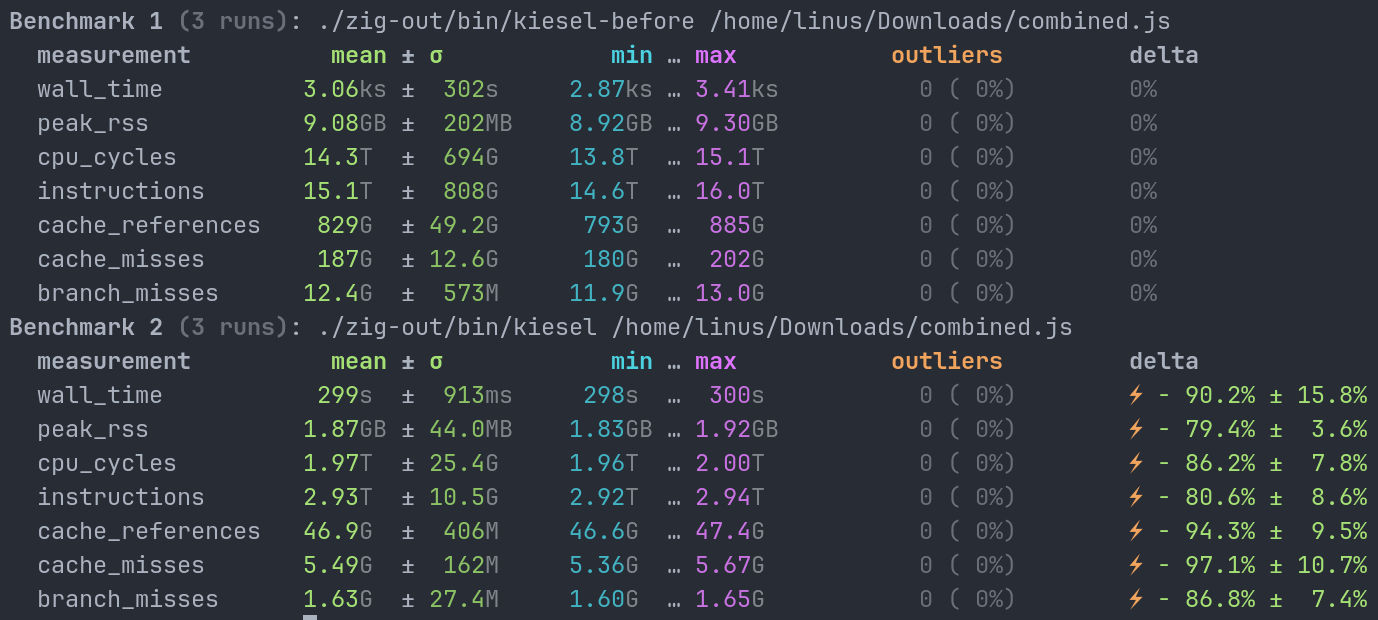
This is using -Doptimize=ReleaseFast builds and running on my AMD Ryzen 7 7840U Framework Laptop.
That was definitely good enough to participate in the nightly Boa benchmark run, so we finally added Kiesel last week. It started with a score of 33, which quickly climbed up to 56:
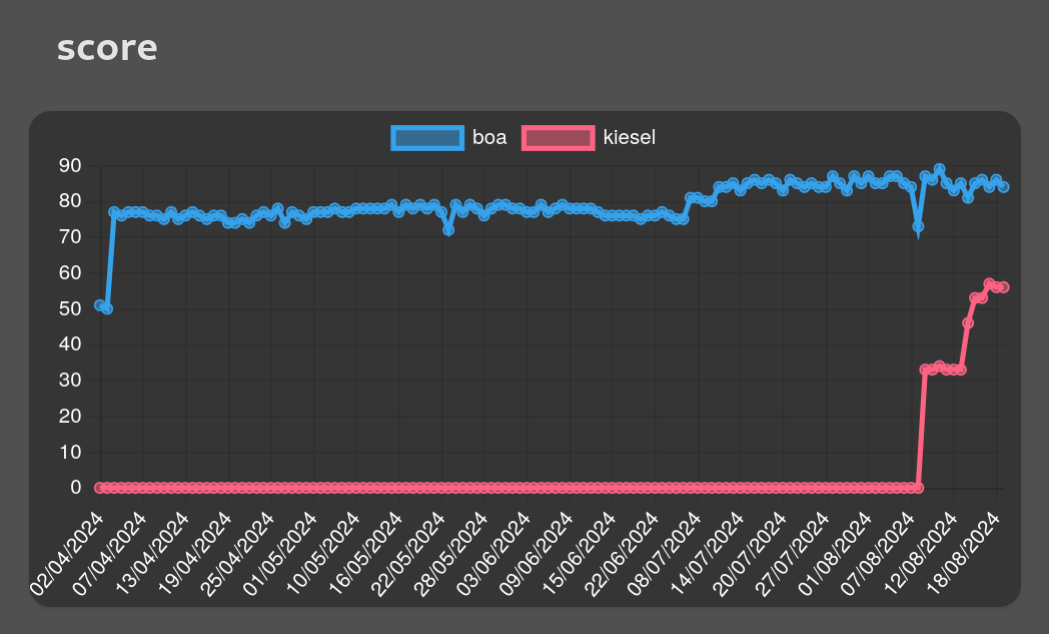
For comparison: Boa scores 85, LibJS 265, duktape 380, and QuickJS 900. V8 with JIT disabled scores ~2400. There is room for improvement :^)
The Future
This is just the beginning, and we're barely scratching the surface here. There's a long list of optimizations to look into in the future, just to name a few:
- NaN-boxing to shrink the fundamental
Valuetype from 16 to 8 bytes - Linear property storage for numeric properties (i.e. arrays) instead of throwing everything into a hashmap
- "Object shapes"/"Hidden classes"
- Fast local variables instead of implementing declarative environments with a simple hashmap and parent pointer like described (but not prescribed!) in the spec
- Storing small strings in the value itself rather than heap-allocating them, we have some 7 bytes left after the tag
A JIT compilerPlease stop suggesting this
I'll have to get back to feature development eventually and we're not aiming for a V8 competitor here, but squeezing more and more performance out of the engine over time will be fun!